Introduction to Microsoft SharePoint Syntex
Table of contents
Back in 2014, Mark Schaefer coined the term “content shock”.
The globally renowned marketing leader was referring to the fact that there was simply too much content being created for people to consume. Since then, we’ve seen more of the world go online to do more things from more devices. A trend that accelerated during the pandemic.
It’s no wonder that International Data Corporation (IDC) predicts the next five years will see more than double the amount of data generated “since the advent of digital storage”.
Faced with this exponential increase, IT leaders are looking for ways to adapt, respond, and keep data secure. While at the same time, looking for ways to unlock the insights hidden within their unstructured content. That’s where SharePoint Syntex comes in.
What is SharePoint Syntex?
SharePoint Syntex is now SharePoint Premium. Microsoft has stated that SharePoint Premium is their advanced content management and experiences platform and the next evolution for Microsoft Syntex.
If you want to learn all the details about SharePoint Premium, download our free eBook “SharePoint Premium: The future of AI-powered content management and experiences”.
With this free 60 page eBook, we aim to comprehensively introduce SharePoint Premium and show you everything you can do including next generation content services, admin capabilities, and AI:
Microsoft SharePoint Syntex is the first Microsoft 365 add-on to be available under general release from Project Cortex. At the time of its late-2019 launch, Project Cortex was described by Microsoft as an initiative that “applies advanced artificial intelligence (AI) to empower people with knowledge and expertise in the apps they use every day”.
Syntex is powered by AI and machine learning models the user creates in SharePoint document libraries. These are no-code, and automate the organizing, classifying, and tagging of all unstructured or semi-structured data entering your document library. Just like your employees do now (depending on their permissions reporting for Office 365).
However, in contrast to your employees, SharePoint Syntex does this at a huge scale, at unprecedented speed. And without ever needing to break for lunch or take a vacation. Plus, because it’s cloud-based, users can advance their knowledge discovery even further. For example, by combining the content with other resources such as Microsoft Graph.
Below we explore two models…
How to use SharePoint Syntex: Form processing model
This model extracts information from structured or semi-structured documents, such as forms or purchase orders. The AI Builder-based form processing engine can recognize and extract dates, personal identifiable information (PII), and other common values.
Upload sample documents (as few as five documents plus one negative sample can be enough to train the model). Then it’s a case of using Power Automate and Power Apps to automate the process. You’ll then have a model you can use for building a database based on the values you define, and from multiple sources. These could be in anything from email to printed forms, with similar layouts for the model to detect, tag, and categorize accordingly.
How to use SharePoint Syntex: Document understanding model
Unlike form processing, these models extract information from unstructured documents such as contracts and letters. The types of files with text-based phrases, so the model can classify and extract what’s necessary.
These are based on Language Understanding models in Azure Cognitive Services and are managed in a SharePoint site for storing and applying your models. This is a Content Center and acts as your site template. You can then apply the models to your chosen SharePoint document libraries.
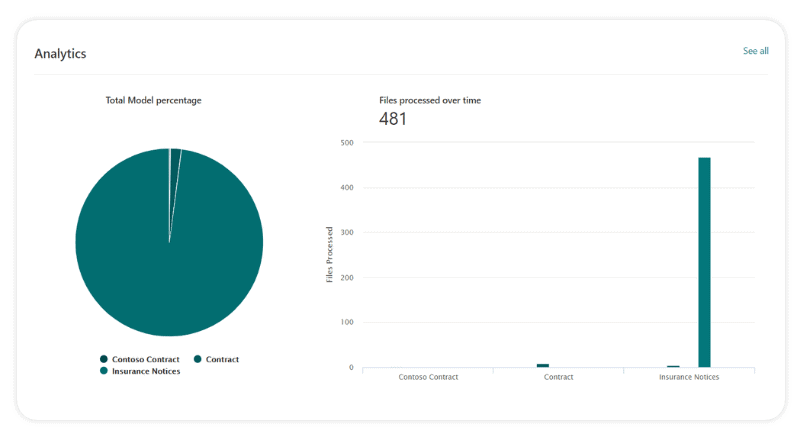
Just like the form processing model, you can start by adding five example files and one negative example to the Content Center. Although the more files you have for training, the better it is for learning. After the Content Center is up and running, you also have the option to use visual analytics to measure your models’ performance.
What are the use cases for SharePoint Syntex?
Syntex also offers the ability to free your organization from many routine and Business-As-Usual activities. Instead of having workers spend time on gathering, sorting, or categorizing information, they’re able to quickly find – and focus on using – the insight contained within.
Naturally, like any new technology, successful adoption involves starting with some typical scenarios in your organization. Common issues, bottlenecks, and areas where SharePoint Syntex can be applied to yield proof-of-concept results to stakeholders. So let’s look at some areas below.
Content
The impact of bad data is well documented. Gartner has found poor data quality to be responsible for an average $15 million in losses per year. For organizations facing these sorts of challenges, SharePoint Syntex looks set to be a game-changer.
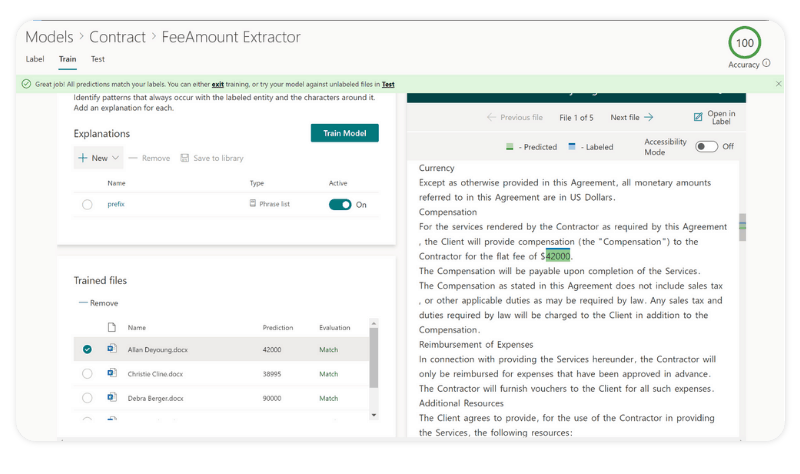
You can use Syntex to organize, classify and label your organizational documents and information. It will then extract relevant, important, and useful data, modeled on how you would manually organize this data. For example, you can create an AI model that provides metadata from files, such as names, customers, or other entities. This can automatically generate schema, lists, libraries, and taxonomy.
What’s more, this isn’t just text-based. You can also use Syntex for image tagging, whether these images are found in SharePoint, OneDrive, or embedded documents such as Word or PDF. This involves using a visual dictionary that contains thousands of common and recognizable objects. When an image is uploaded, Syntex uses object recognition to automatically recognize and tag the image. Handwritten text can also be recognized and processed, using Optical Character Recognition.
How Syntex speeds up processes
Time-tracking software Clockify found up to 90% of employees are “frequently burdened with boring, recurring tasks.” With bored staff twice as likely (pdf) to exit a company, this can prove expensive. For US businesses, the cost of replacing an employee is reportedly 1.5–2X their salary.
Imagine you have an ERP system, which involves manually processing orders. These need to be validated, reconciled, and fulfilled. They may come in via email, paper, or an app. Deploy SharePoint Syntex (AI Builder credits are also required), and you remove the requirement for staff to spend time on many of these routine processes.
The result is you can process data, structured and semi-structured. In a faster, more efficient, and more secure way.
How Syntex supports compliance
Manually completing routine processes can sometimes lead to ‘fat finger’ mistakes, where wrong data is manually inputted. In some cases, such as the Citigroup/Revlon case, this can cause multi-million-dollar problems.
For auditing, you could create some processes for SharePoint Syntex to check receipts comply with policies. Any that don’t comply can be flagged up for manual checking. Everything that does comply can be processed as normal and according to your governance and reporting rules.
For security, you could use Syntex to build models that automatically apply Microsoft Information Protection labels to your documents. These can be consistently applied across multiple tenants, SharePoint document libraries and sites, for sensitivity or retention. This way, certain documents can’t be deleted for a set period.
How to use SharePoint Syntex to solve legacy challenges
Of course, with such transformational technology, there are challenges.
People
Some of the challenges start with the people that use it. Many of us are still used to storing and archiving files as if they’re physical documents. That means inconsistencies in how files are stored, with the risk of error, and of course security risks.
Data
There’s also the fact that data continues to arrive at increasing volume, variety, and velocity. Although… more data should mean more insights, right? Well, an IDC report found organizations are generating more data, yet saving less.
Security
As organizations migrate more and more information into Microsoft 365, the need for a secure method becomes ever more crucial. Especially when you consider the often hybrid nature of organizational cloud-based working. So many endpoints, sites, and infrastructures, with more assigned Office 365 users working across multiple locations and devices.
SharePoint Syntex: How to keep data secure
So far, we’ve looked mainly at the advantages and opportunities for organizations using Syntex. However, we should also highlight the fact that there’s a significant learning curve involved. As Forrester says, “This is not a feature to be flipped on and just work. It will require investment in time and internal expertise.”
Alongside the expertise required, there’s also a big question about security. Take the vast volumes of data. Add the likelihood of sensitive information being held in SharePoint. Then combine this with building models where there will naturally be far less manual involvement.
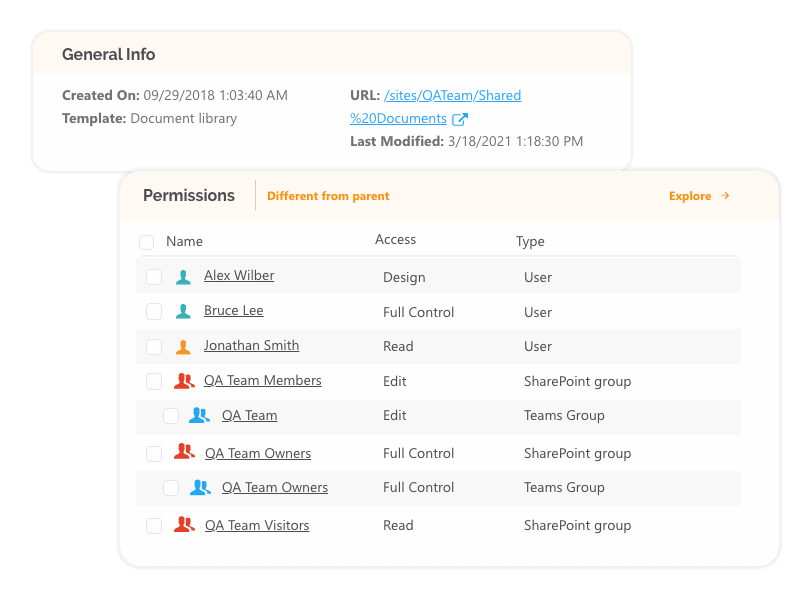
Maintaining visibility of this information, and supporting who keeps control over Office 365 access, requires a different type of solution. One that provides:
- Centralized governance
With the control and transparency to satisfy compliance managers and CSOs, auditors, admins and users. - Reporting in seconds
Where you can quickly see who has access to what content within your SharePoint document libraries. - Managed external sharing
With Syntex likely to be processing so much structured and unstructured data, you need a way to manage users, guests, plus control of sharing permissions. - Analytics
Advanced tools to identify any unusual patterns relating to user activity within sites, and adoption of Office 365 within your business. - Simple exports
You’ll probably want to share SharePoint Syntex insights in multiple formats. Perhaps Excel for year-end accounting or PDF for invoice reconciliation. - Provisioning control
It’s essential to have a method for controlling who creates Content Centers for use with Syntex, and who builds models for use with your data.
As you can see from that list, there are many considerations around security, governance, and compliance. Of course, we wouldn’t expect you to spend time looking around for a solution that will meet all those needs. Instead, we’d like to help you out and introduce you to Syskit Point. It can be a central point for your Microsoft 365 governance and security. Start your free trial to see how it can make your life easier.

