SharePoint 2013 search topologies explained
Table of contents
In this post, we’re going to overview the components in SharePoint 2013’s Search Topology which can be very complex to configure. Here you will also find an overview and some useful instructions on how to configure, monitor and document them.
Search Topology Components
In SharePoint 2013, there are numerous components in Search Topology:
- Search Admin Component
- Index
- Crawler
- Content Processor
- Analytics Processor
- Query Processor
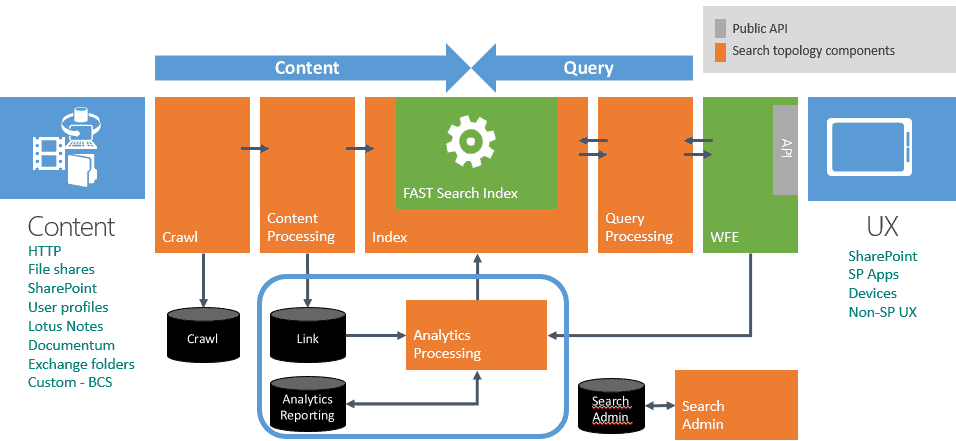
Read more about these components:
The search administration component runs the system processes that are essential to search. This is the component that performs provisioning to add and initialize instances of other search components.
The index consists of one or more index partitions, and each can have multiple replicas: Index partitions: You can divide the index into discrete portions, each holding a separate part of the index. Search index is the aggregation of all index partitions.
These index partitions are stored in a set of files on the disk.
Index replicas: To achieve fault tolerance and redundancy, you can create additional index replicas for each index partition. These index replicas can be distributed over multiple servers.
The Crawl Component crawls the content based on what is specified in the crawl databases. To retrieve information, the crawl component connects to the content sources by invoking the appropriate indexing connector or protocol handler. After retrieving the content, the crawl component passes crawled items to the content processing component.
The Content Processing Component processes crawled items passed by the Crawler, and sends these items to the Index. It performs operations such as document parsing and property mapping. It also performs linguistics processing and transforms crawled items into artifacts that are included in the search index.
The Analytics Processing Component performs both search analytics and usage analytics. This component uses information from these analyses to improve search relevance, create search reports, and generate recommendations and deep links.
Query Processing Component analyzes and processes search queries and results. When the query processing component receives a query, it performs linguistic processing first (like word breaking and stemming), then analyzes and further processes the query to optimize precision, recall, and relevance. In the end, the processed query will be submitted to the index component.
The index component returns a result set based on the processed query, and the Query Processor in turn processes that result set, before returning it to the search front-end.
Configuration
As you can see, Search Topology in SharePoint 2013 is complex. So is its configuration – but if you understand the basics it gets much easier and simpler.
First of all, let’s see an example. On the screenshot below, you can see the Search Topology of a customer of mine:
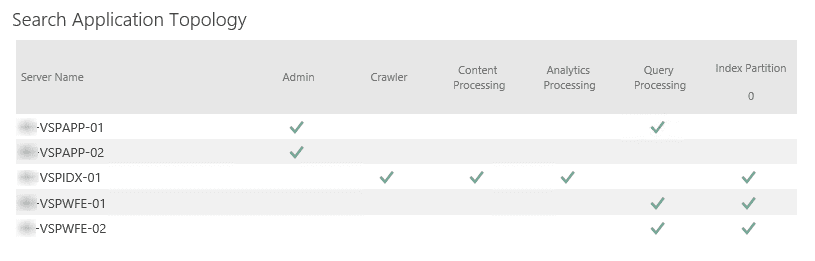
In this environment, we have five servers: two Applications, one Index and two Front-Ends. We assigned the following rules to each:
- Both App Servers are configured to be Search Admins.
- The Index Server has the Crawler, Content Processing and Analytics Processing roles.
- The primary App server and both Front-End servers are responsible for Query Processing.
- Index server and both Front-End servers store a replica of the index.
The current topology is always displayed on the Search Service Application in Central Administration, although the configuration can be done via PowerShell only.
Steps for achieving the Topology changes above:
- Add a new Index Component
- Add a new Crawl Component
- Add a new Content Processing Component
- Add a new Analytics Component
- Add a new Admin Component
For each of these steps, we have to clone the current Search Topology, add the proper component(s) and then activate the cloned topology. With these steps, we always have one active topology, although we might have multiple inactive topologies too, and can activate any of them at any time. This can be very helpful when doing performance tests, for example.
The best step-by-step on Search Topology configuration has been written by Steve Mann on his blog.
Monitoring
Due to the complexity of Search Topology in SharePoint 2013, its monitoring is essential in any environment. Let’s see what options we have:
- Health information on the Search Service Application for Search Topology components. It gives us information on each component by color-coding (green – yellow – red).
- The PowerShell command Get-SPEnterpriseSearchStatus provides more details, including detailed diagnostic information for quick troubleshooting.
- We have Search Health Reports in Search Administration / Diagnostic, where we can check the performance and health of each component. Some reports here: Query Performance, Query Latency, Crawl Rate, etc.
If you’re a Search Admin, it’s better to add checking the health of the Search Components to your daily routine, preferably in the mornings. As seen, you can do this by visiting the SSA on the Central Administration or by PowerShell. The best way, of course, is to use a scheduled job to check the status of each component and send an alert if something is degraded or failed.

Documenting Search Topology
Documenting the configuration steps and the final topology has always been a challenge. But with the help of Documentation Toolkit for SharePoint, it gets easier than ever – let me show you how.
The latest version of the Toolkit contains a great feature for documenting Search topology. For example, let’s say my farm consists of the following five servers:
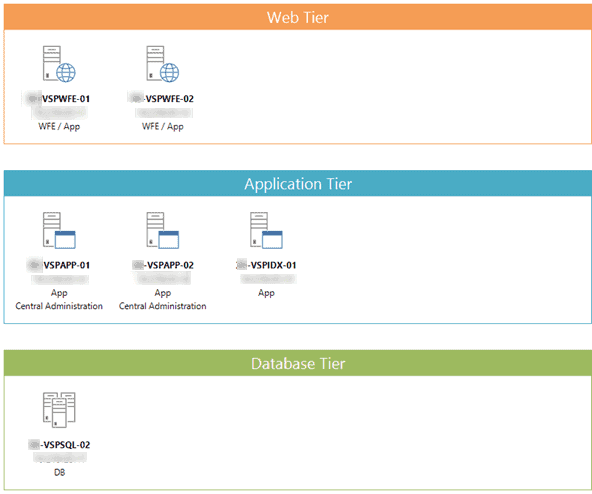
In the beginning, the farm was configured to use only the primary App Server hosting all the Search components, but in this enterprise environment, it had to get scaled out, of course.
The following screenshot shows what the SP Documentation Toolkit sees, including:
- the initial, one-server search topology as an inactive one (Topology #1).
- the final, active topology, which consists of five servers (Topology #14).
- each inactive topologies, which have been created during the incremental configuration (Topology #2 – Topology #13).
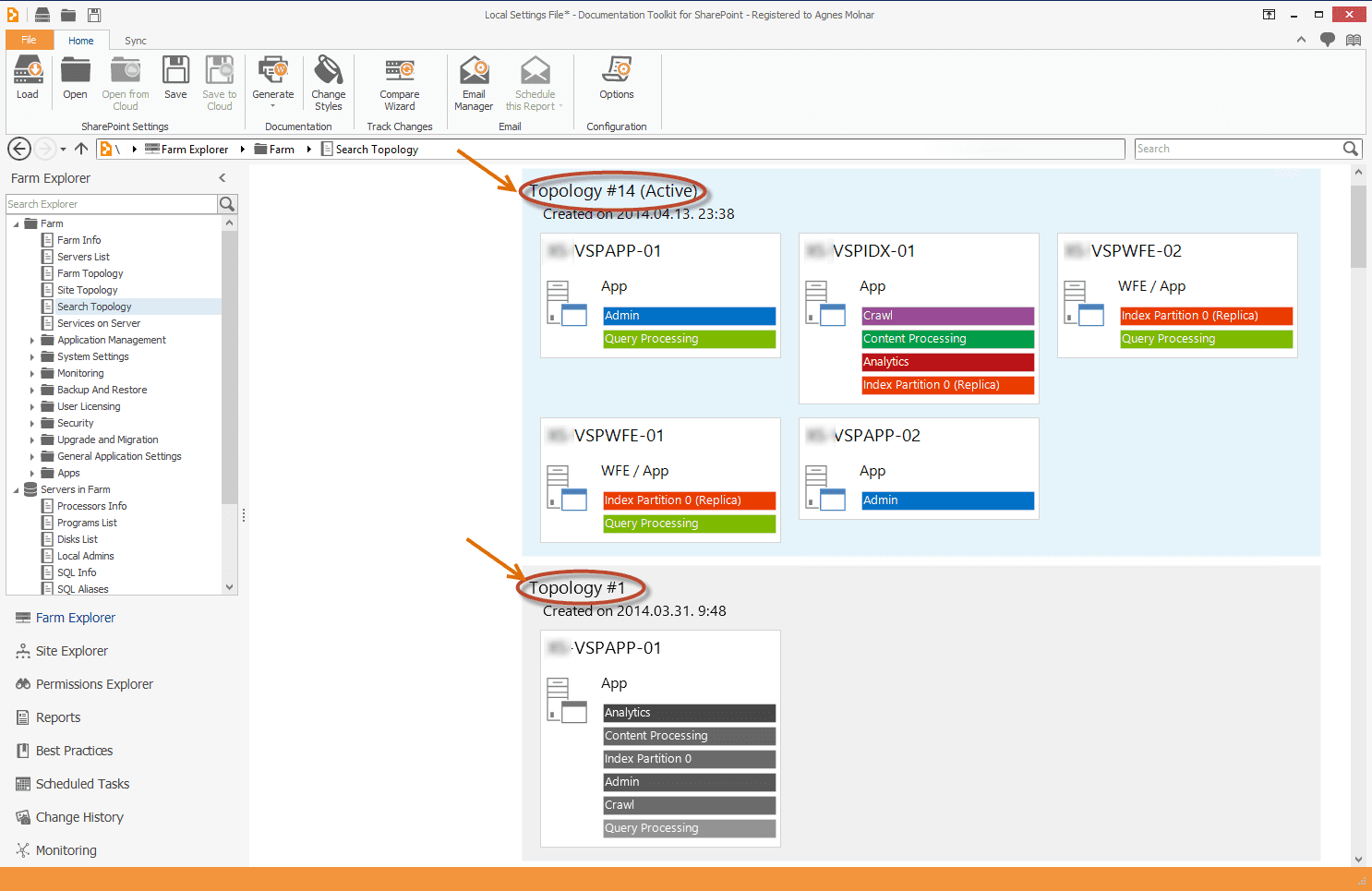
Of course, you might have a smaller number of topologies if your environment is smaller, and/or if you’ve made your changes in fewer steps, or if you deleted some of the temporary topologies.
References:
http://www.microsoft.com/en-us/download/details.aspx?id=30374
http://technet.microsoft.com/en-us/library/jj219738%28v=office.15%29.aspx
http://blogs.technet.com/b/meamcs/archive/2013/04/09/configuring-sharepoint-2013-search-topology.aspx
http://stevemannspath.blogspot.com/2013/06/sharepoint-2013-scaling-out-enterprise.html

